
This integration of external information boosts the AI’s ability to provide context-aware responses. When developing a prompt tailored to interact with your data, the following steps are key:
One key step in this whole process is using something called a Vector Store. Think of it as a database where you save data in a way that lets you search very efficiently later on. Let’s say you run a law firm with tons of clients and all sorts of legal stuff going on. Managing all that info can be daunting. That’s where tools like LLMs and Prompt Engineering can make life way easier. Envision the ability to interact with your legal documents directly, asking questions like, “What are the main points of this case?” and receiving concise answers, bypassing the labour of poring over countless pages. While the legal scenario illustrates its value vividly, the utility of Vector Search isn’t confined to that; it’s a significant asset in any context where vast data is at play.
Vector stores, also known as vector databases, are key components for managing, querying, and retrieving large volumes of high-dimensional vector data. Choosing a vector store involves considering factors such as performance, scalability, precision, ease of use, integration with your existing tech stack, cost, support availability, security, and use case fit. If you’re using a cloud service, using their native vector store can provide improved integration and possibly better performance, but it should still meet your specific requirements. Azure Cosmos DB for MongoDB vCore is one of the many existing vector stores out there, and with the pre-existing data in Cosmos DB, one can now employ Vector Search to smoothly incorporate AI-driven applications, particularly those that utilize OpenAI embeddings. These embeddings are basically numerical representations of words or phrases, crafted mathematically to enable comparison and analysis of textual content.
This example demonstrates the process of ingesting and vectorizing documents, specifically PDFs, in preparation for a subsequent vector search. We’ve employed a Blob Storage trigger in this scenario. This ensures that the Azure Function springs into action whenever a new blob appears or an existing one gets updated. Within this setup, the blob’s content is fed into the function. It’s worth noting that while there are myriad tools and methods to extract text from various document formats, for the sake of this demonstration, we’ve honed in exclusively on PDFs.
Initially, the “Ingest” Azure Function is triggered whenever a blob in the “documents” container is either added or updated.
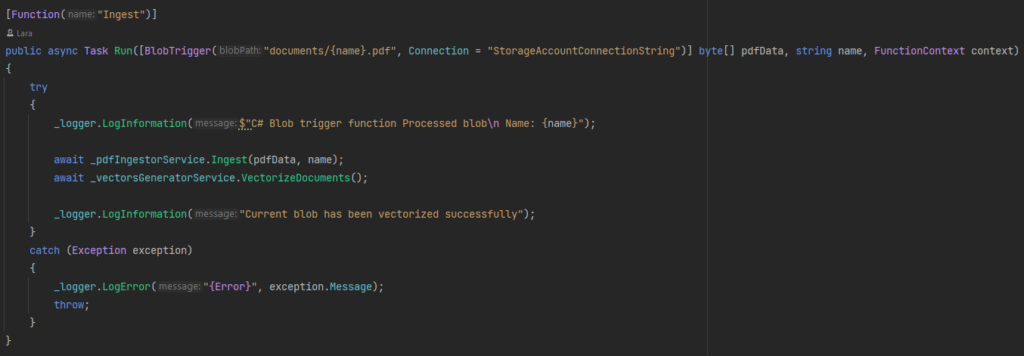
First, the document undergoes ingestion, followed by vectorization. During ingestion, text is extracted and subsequently stored in a collection called “docs”. It’s worth noting that you can customize the collection name to your preference, or even maintain multiple collections, based on your specific use case.
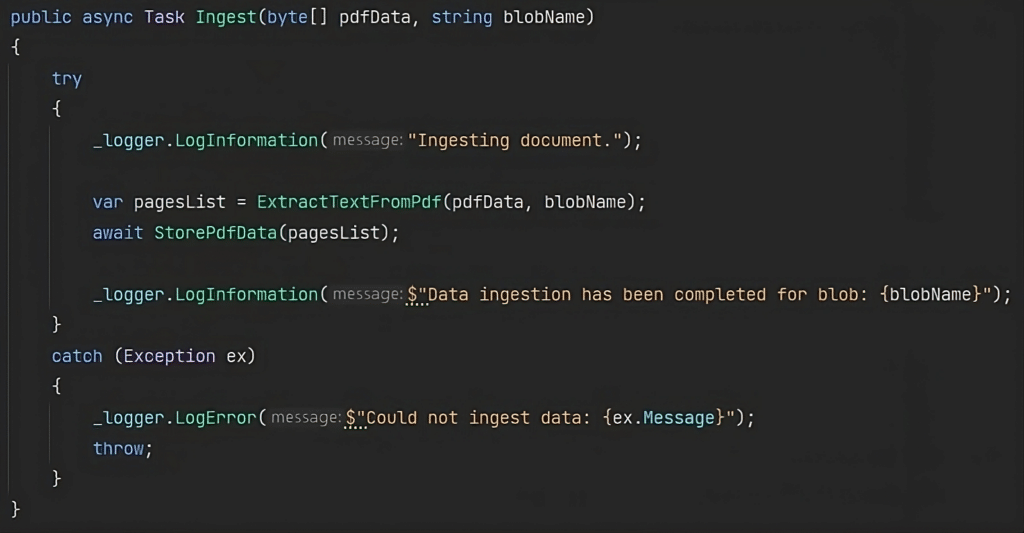
After the successful ingestion of the document, the subsequent step focuses on generating embeddings from the ingested data.
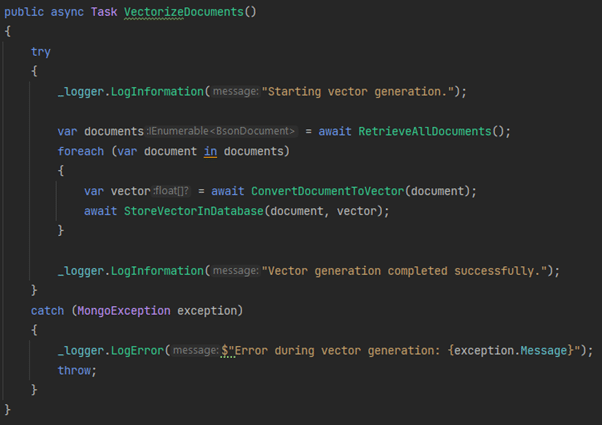
In the vectorization phase, the process begins by pulling all documents from our target collection, aptly named “docs” in this scenario. Leveraging the “text-embedding-ada-002” model and an associated embeddings API, we convert this data into vector representations. These vectors are subsequently stored in the “vectors” collection. For the creation of a vector index, we’ve used a specific template.

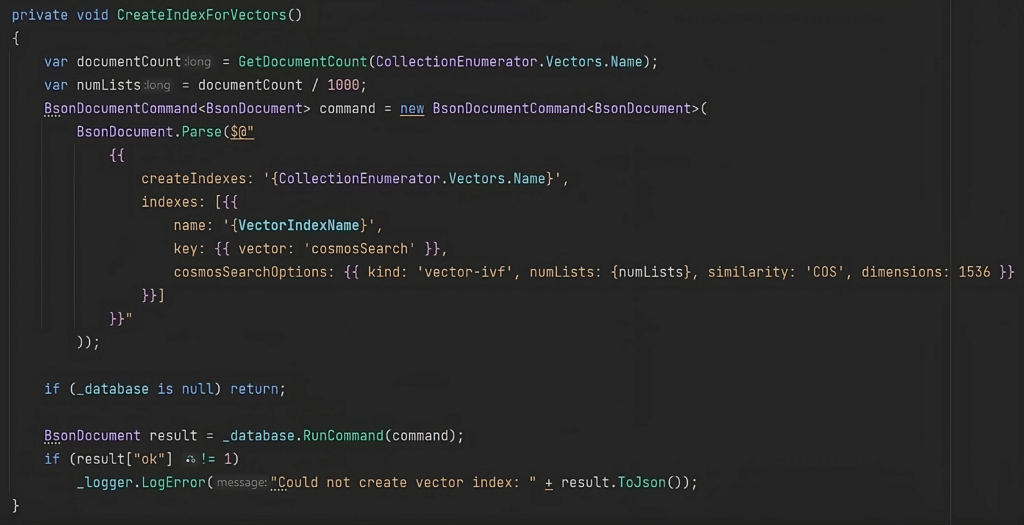
Referring to the provided template, one must specify the collection name. In this hands-on example, we’ve chosen the name “vectors” for the collection. For the index, the label “vectorSearchIndex” was employed. The “numLists” attribute indicates how many clusters the Inverted File (IVF) index uses to organize vector data. Microsoft’s guidance suggests setting it at rowCount()/1000 for datasets containing up to 1 million rows, and to the square root of rowCount when datasets surpass this threshold. For the “similarity” property, we opted for “COS” (cosine distance). This metric is frequently favoured for textual data, especially when dealing with intricate vectors like word embeddings, given its ability to account for vector magnitude fluctuations.
In this demonstration, we added two documents to the container. Both were processed smoothly, undergoing ingestion and vectorization. The subsequent images present the resources we created in Azure.
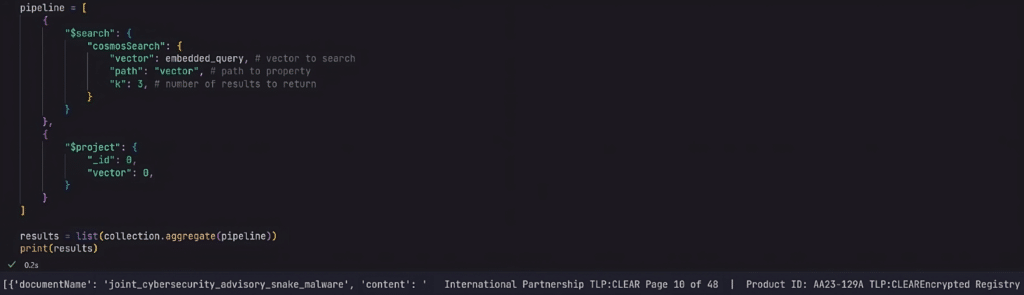
With the data in place, it’s possible to perform a vector search using the $search aggregation pipeline stage in a MongoDB query. As per Microsoft’s documentation, the “cosmosSearch” operator is the tool to facilitate this.

To provide a hands-on demonstration of vector search, we’ve developed a straightforward Jupyter notebook. This facilitates interaction with the ingested and vectorized PDFs. Stored in the account, these documents pertain to security and originate from the Joint Cybersecurity Advisory. This U.S. government report, a collaboration of agencies like CISA, FBI, and NSA, outlines emerging cyber threats and proposes defensive measures. The first document, titled “2022 Top Routinely Exploited Vulnerabilities”, offers guidelines on reporting cybersecurity incidents and minimizing risks through the deployment of security tools and administrative strategies. The second, “Hunting Russian Intelligence Snake Malware”, explores the Snake malware, a tool employed by Russia’s Federal Security Service for cyber espionage.
With this data available, we can begin posing questions. By employing vector search, we can extract the full value of the information. This technique is adaptable and suitable for various contexts and diverse data sets. In our subsequent example, we started by initializing the environment. After that, we instantiated the MongoDB Python client.
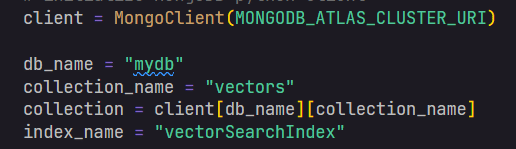
Next, we need to instantiate our vector store, which is the Azure Cosmos DB for MongoDB vCore. As part of this process, we’ll feed the embeddings model into the vector store instance.

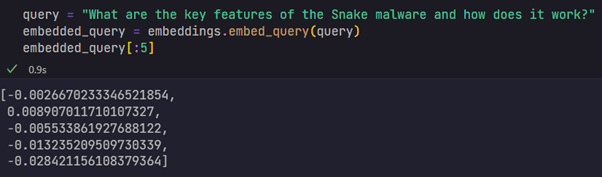
The next step is to come up with a question that you’d like to be answered and then, embed it. With this information, a similarity search is performed between the query and the documents, and the results are the “k” most similar items to the embedded question. Notice that the document that contains the content matching our question was successfully identified, along with a snippet that relates to the answer.
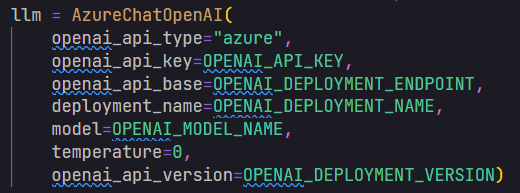
After that, you can set up an instance of one of LangChain’s chat models. LangChain is a framework for developing applications powered by language models. In this example, the “AzureChatOpenAI” class was used, which is a wrapper around Azure OpenAI Chat Completion API. The model accepts input as a chat dialogue, where each role and their respective messages are clearly defined. Based on this conversation, it then produces the subsequent chat response or continuation. In this example, the system’s role offers the initial directives to the model. On the other hand, the user’s role, also referred to as the human’s role, contains the question that will be answered by the model.

Complete answer from the model: “The Snake malware has several key features, including the use of encrypted registry key data, a kernel driver and custom loader, and a covert store. Upon execution, Snake’s WerFault.exe attempts to decrypt an encrypted blob within the Windows registry that includes the AES key, IV, and path used to find and decrypt the file containing Snake’s kernel driver and kernel driver loader. The installer drops the kernel driver and a custom DLL into a single AES encrypted file on disk, typically named “comadmin.dat” and stored in the %windows%\\system32\\Com directory. The covert store is used to hide Snake’s files and is detected by encrypting each possible initial filesystem byte sequence with CAST-128 using the key obtained from the registry and searching for any file with a size that is an even multiple of 220. Snake also uses a queue file with a predictable path and filename structure, in addition to being high entropy. Memory analysis is an effective approach to detecting Snake because it bypasses many of the behaviors that Snake employs to hide itself.”
At its core, vector stores focus on digging deep into data meanings, making searches smarter, especially with vast amounts of data. They not only improve user experiences with enhanced search results but also open up pathways to insightful analytics. This empowers businesses to make informed choices, fine-tune their marketing, and thrive in competitive arenas. The example shown here is a simple step-to-step process of one of the many things that can be done with this data, from the ingestion point to its usage in a prompt, leading to insightful outcomes.






