HomeWhat is machine learning? Types, practical applications and how does it work
What is machine learning? Types, practical applications and how does it work
Published: 11/04/2024
Author: Raquel Hernando
What is machine learning?
Machine learning is the application of statistical, mathematical and numerical techniques to gain knowledge from data. These insights can lead to summaries, visualisation, clustering or even predictive and prescriptive value on datasets.
Regardless of the beliefs that surround it, it is important to highlight that machine learning is not a replacement for analytical thinking and critical work in data science, but rather a supplement to support more responsive decision-making.
Furthermore, machine learning is also characterised as a set of diverse fields and a collection of tools that can be applied to a specific subset of data to address a problem and provide a solution to it.
What’s the difference between AI and machine learning?
Machine learning and artificial intelligence, as well as the terms data mining, deep learning, and statistical learning are related.
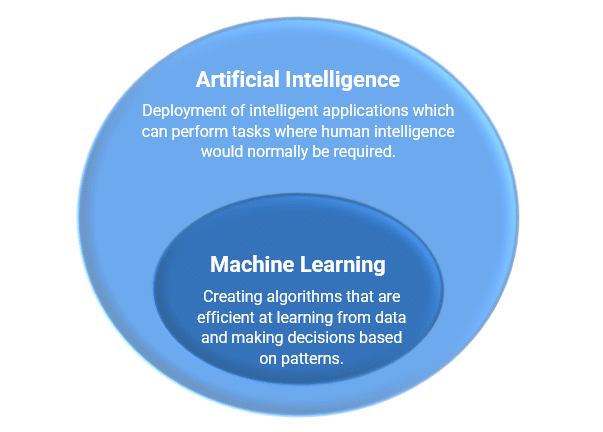
Artificial intelligence is the ability of a computer system to emulate human cognitive functions including thinking, learning and problem-solving. Using AI, a computer system applies logic and mathematics to imitate the same reasoning that people use to make decisions and learn from new information.
After considering machine learning as the process of using mathematical models of data to help a computer learn without direct instructions, allowing a computer system to continue to learn and improve itself based on experience, machine learning can therefore be understood as an application of AI.
Types of machine learning
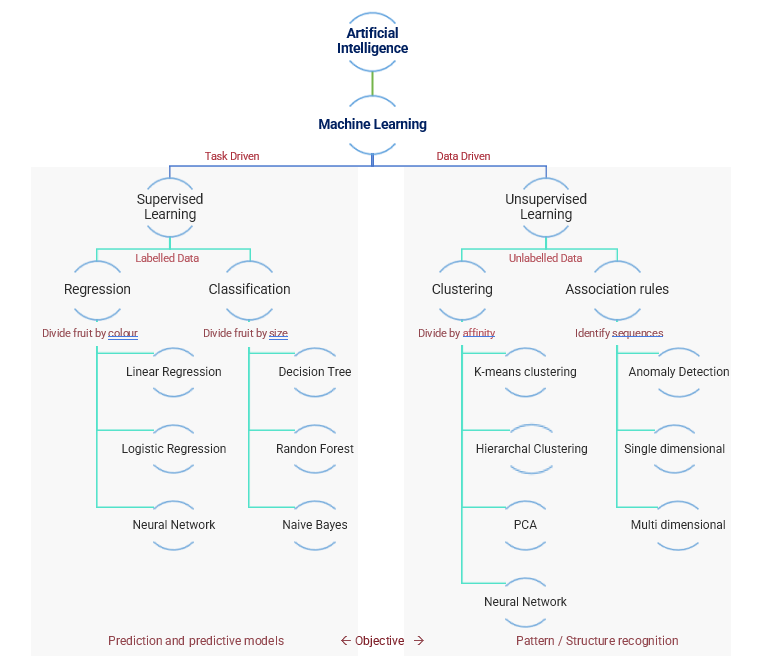
Machine learning refers to a set of techniques used commonly for solving a range of real-world problems with the aid of computational systems which have been programmed to learn how to solve a problem rather than being explicitly programmed to do so. Overall, we can distinguish between supervised and unsupervised machine learning.
The main differences we can distinguish between these learning models are the following:
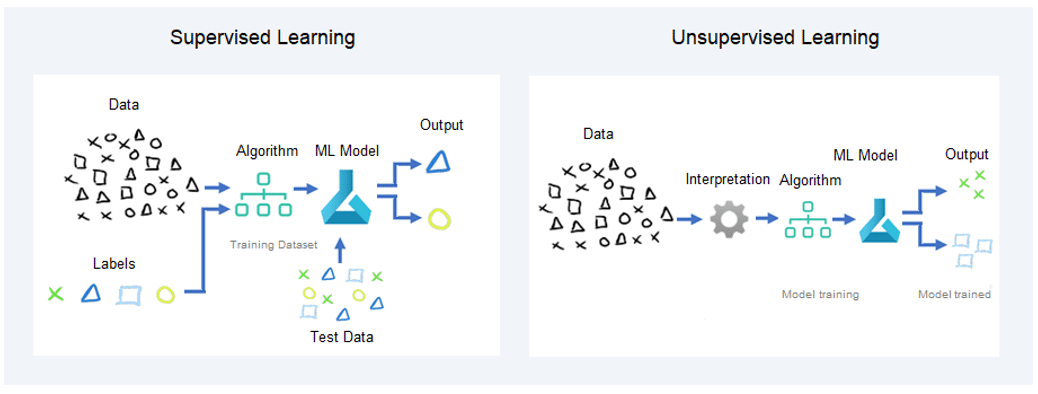
Purposes: Supervised learning intends to predict or classify data based on labelled data, while unsupervised learning pretends to figure out patterns or hidden structures in the data.
Data that is labelled and data that is unlabelled: The main difference between labelled and unlabelled data consists in the availability of labelled data. Supervised learning operates on labelled data, while unsupervised learning works on unlabelled data.
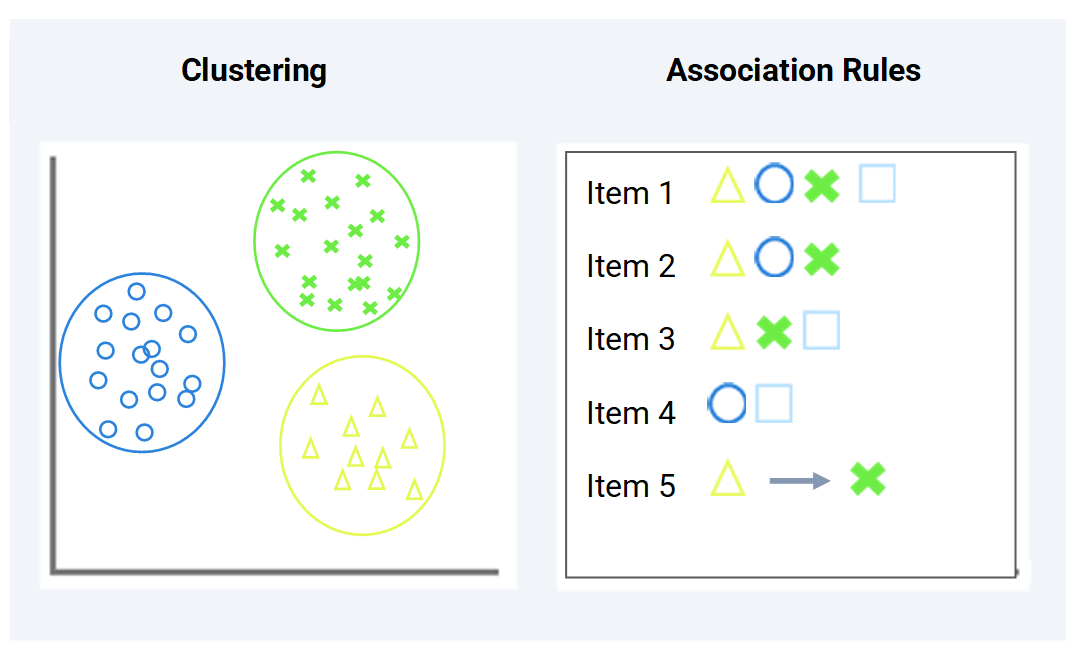
Tasks: Supervised learning covers performing tasks such as classification and regression, while unsupervised learning involves clustering and association rules.
Supervised learning
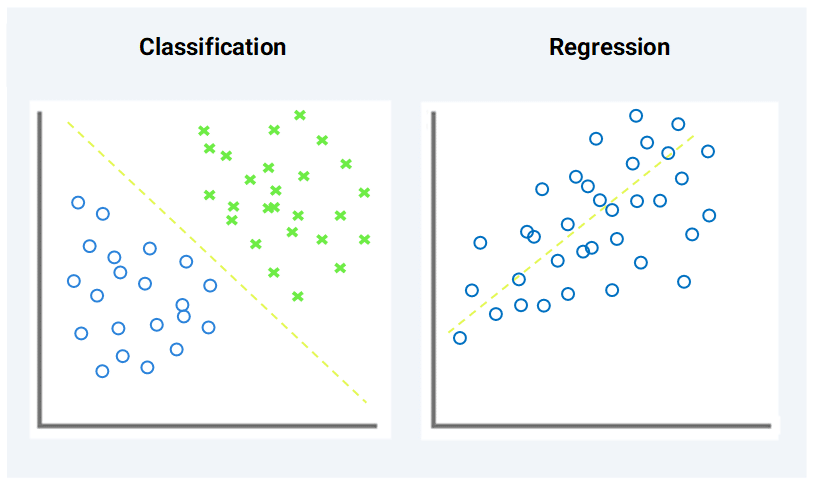
Supervised learning can be separated into two types of problems when data mining—classification and regression:
Regression: It’s associated with continuous data. The output values predicted in regression are solid numbers. This is involved in problems such as predicting the price of a house or the trend of stock prices at a given point in time, etc.
Classification: It involves converting an incoming value into a discrete value. In classification problems, the result usually comes in the form of classes or labels. As an example, we can try to predict whether it is going to rain today or not.
Supervised learning algorithms
Regressionalgorithms: Refers to a model that predicts continuous (numerical) values, in contrast to classification, which mainly classifies data.
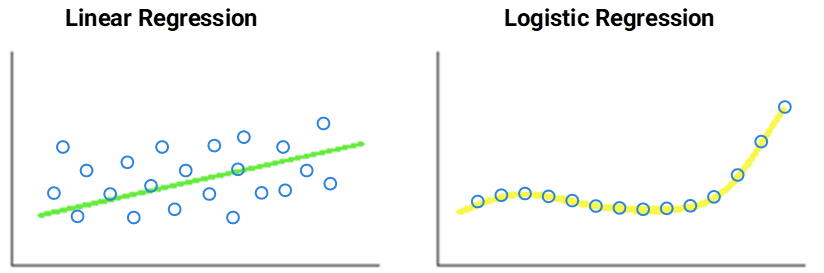
Linear Regression: A common statistical method for modelling the relationship between some “explicative” variables and some actual-valued result. Posed as a learning problem, one must work on a hypothesis regarding the linear regression predictors, which are obtained by means of a set of linear functions.
Logistic Regression: It’s primarily concerned with probabilities. It takes historical data and measures the likelihood of something happening as a function of the inputs. For example, you could argue that there is an 85% chance of customers buying a product as a function of their age and income.
Naïve Bayes: Based on Bayes’ theorem, is a probabilistic classifier that focuses on working with simplifications, which are summarised in the assumption of independence between predictor variables. It is thus assumed that each feature of the data points generated within each class is independent, hence the descriptor “naive.”
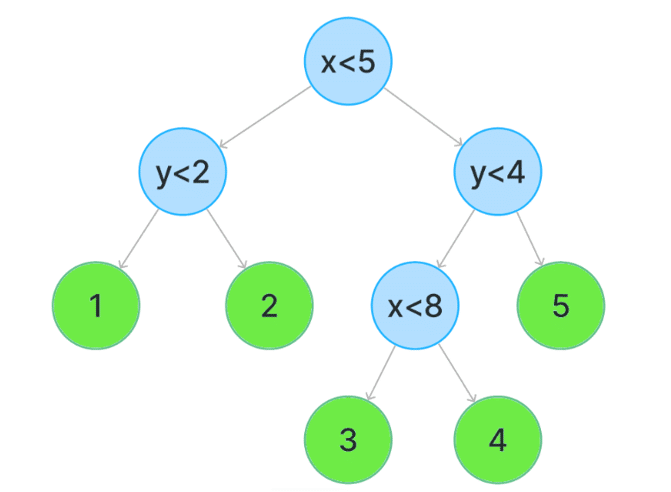
Decision Tree and Random Forest: A decision tree is a predictor that predicts the label associated with an instance by focusing on the binary classification scenario. Typically, the splitting is based on one of the features of X or on a pre-determined set of splitting rules depending on the label contained in each leaf of the branch on which it is moving.
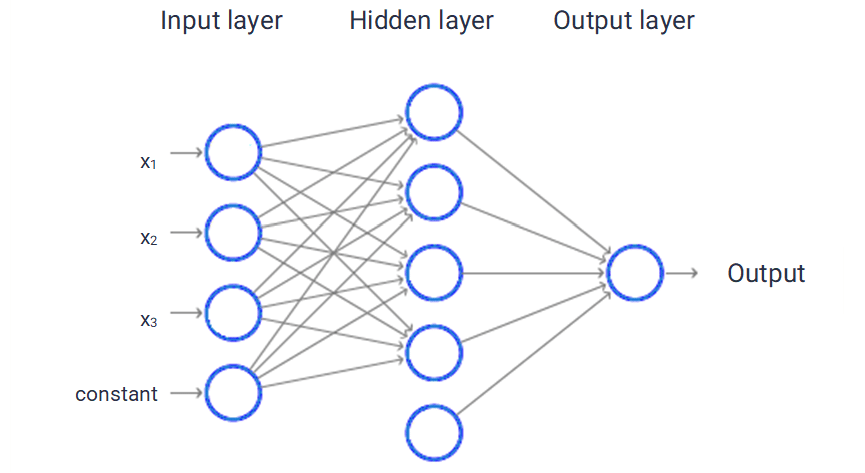
Neural Network: Programming model inspired by the structure of neural networks in the brain. Composed of many basic computing devices, called neurons, which are connected to each other in a complex communication network, through which the brain becomes capable of performing highly complex computations. Neural networks are broadly useful for problems in supervised and unsupervised learning.
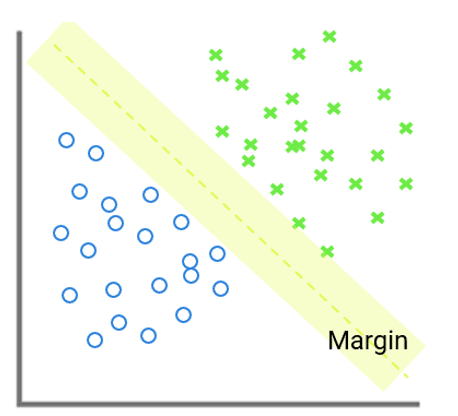
SVM: Also known as a support vector machine. The defining goal of the SVM is to provide as much distance as possible between the data points and the decision boundaries.
Unsupervised learning
The unsupervised learning algorithm can be further categorised into two types of problems:
Clustering: This technique is guided by the goal of discovering structures in our data. The identification of groups or clusters within data points that are similar is a useful and widely used unsupervised technique.
Association rules: It’s a type of unsupervised learning technique that tests the dependence of one data element on another. In this way, this model tries to find interesting relationships or associations between variables in the dataset.
Unsupervised learning algorithms
Neural Network: As discussed in the previous section, neural networks are widely useful for both supervised and unsupervised learning problems. Working from one or another will depend on the problem being faced and the data that is available to provide a solution to the problem.
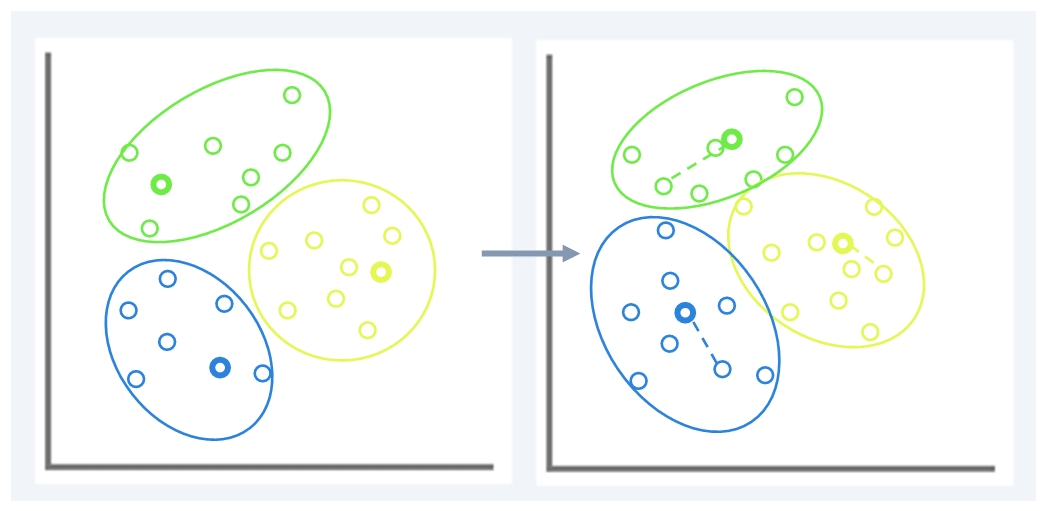
K-means clustering: This technique is motivated by the purpose of discovering data patterns, identifying groups of similar data items is a useful and powerful unsupervised technique. This algorithm focuses on analysing randomly selected cluster centres in the dataset. Each data point is then assigned to the closest cluster. This will work with the mean of the values that make up each cluster.
Hierarchal Clustering: It’s an algorithm that consists of creating clusters that have a top-down predominant order. This algorithm works on grouping similar objects into clusters. The goal is to combine a set of groups where each group is distinct from another group, but the items within each group are broadly similar to each other.
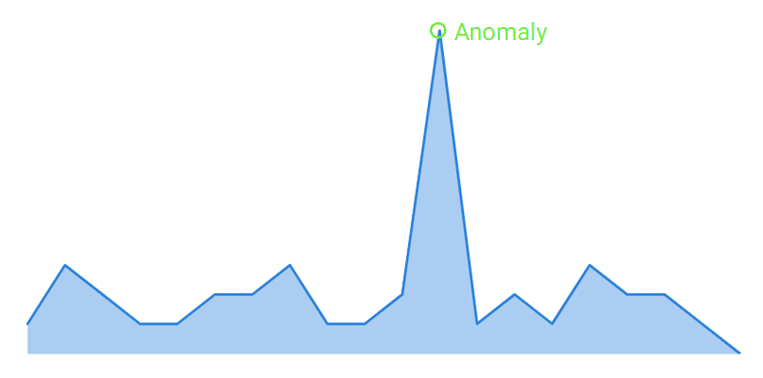
Anomaly Detection: It’s a type of binary classification where the data set is composed of anomalous and non-anomalous data points. The target of anomaly detection is to identify unusual data points.
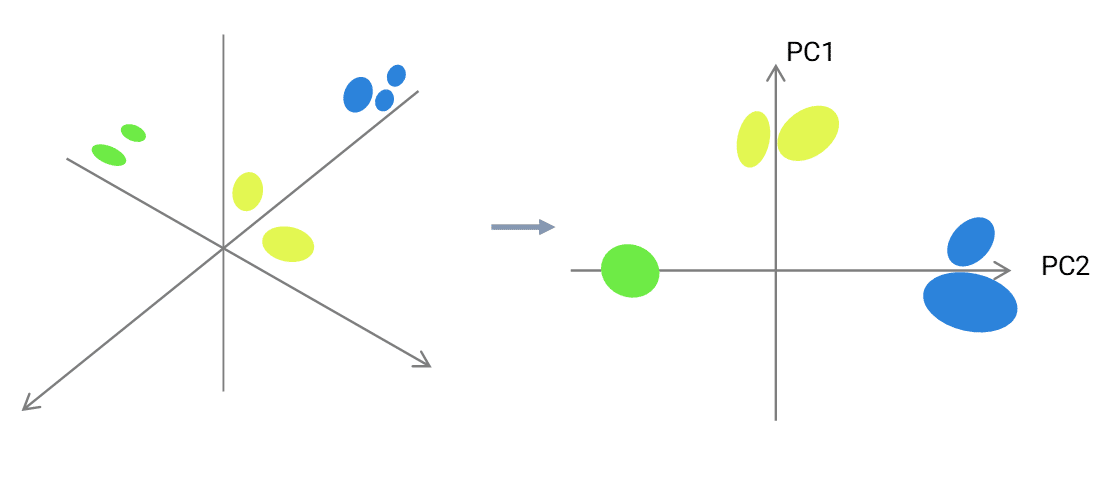
Principal Component Analysis: the key concept of principal component analysis (PCA) is based on the assumption a data set can be linearly projected over a subspace and not lose too much information.
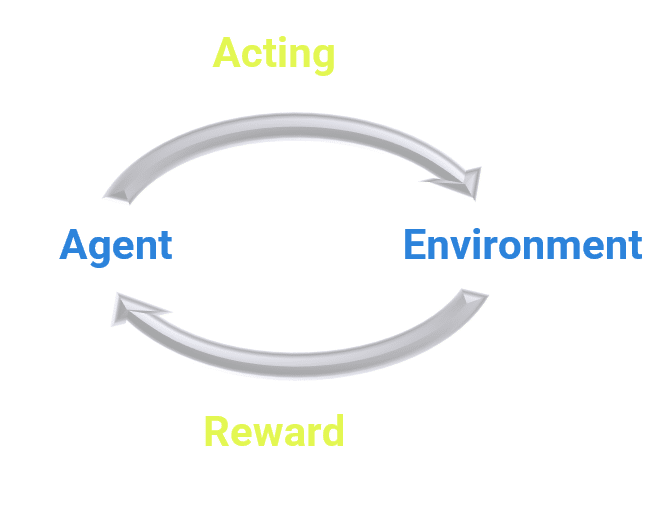
Reinforcement learning
Reinforcement learning is an area of machine learning. Its concern is to take appropriate actions to optimise the reward in each situation. Many computer programmes and machines apply it to find the optimal performance or path to follow in a specific situation.
Reinforcement learning contrasts with supervised learning where the training data contains the key to the response, and the model is trained with the right answer, while in reinforcement learning there is no feedback, but the reinforcement agent chooses what to do in order to perform the task.
Decision-making process
Practical applications of machine learning. What can machine learning do?
Depending on the situation we are dealing with, we will have to choose between one method or another. For example, if we want to determine the number of phenotypes in a population, organise financial data or identify similar individuals from DNA sequences, we can work with clustering.
On the other hand, if the problem is about predicting whether a particular email is spam or predicting whether a manufactured product is defective, we are trying to identify the most appropriate class for an input data point, so using a classification algorithm would be most appropriate.
Other situations that can be tackled are predicting house prices, estimating life expectancy, or inferring causality between variables that are not directly observable or measurable, in which case regression would be the most convenient algorithm to work with.
We also recommend this blog on machine learning for data analysis to find out how it can work closely with apps like Power BI to enhance any company’s operations. Seeing business analytics and data science working together can be truly fascinating.
Azure machine learning
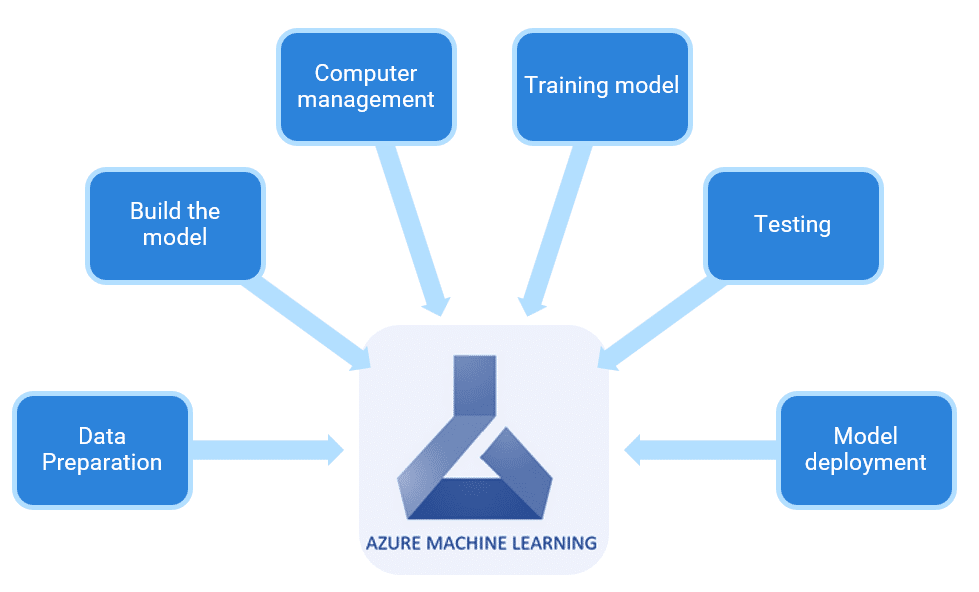
Azure Machine Learning is a cloud service for automating and managing the entire lifecycle of machine learning (ML) projects. This service can be used in your daily workflows to train and deploy models and manage machine learning operations (MLOps).
Azure Machine Learning has tools that enable you to:
Collaborate with your team across notebooks, serverless computing, data and environments.
Deploy ML models effectively at scale and manage and govern them efficiently with MLOps.
Run machine learning workloads in any location with built-in governance, security, and compliance.
What are advanced ensemble learning ideas?
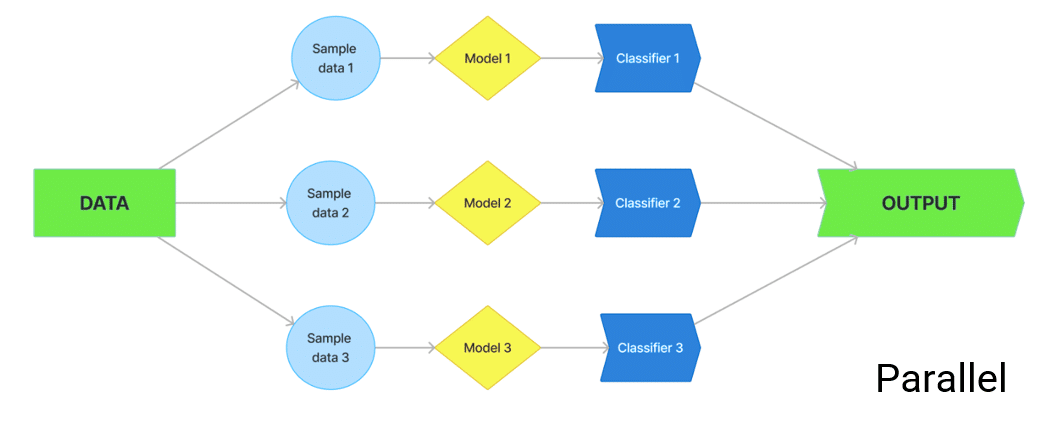
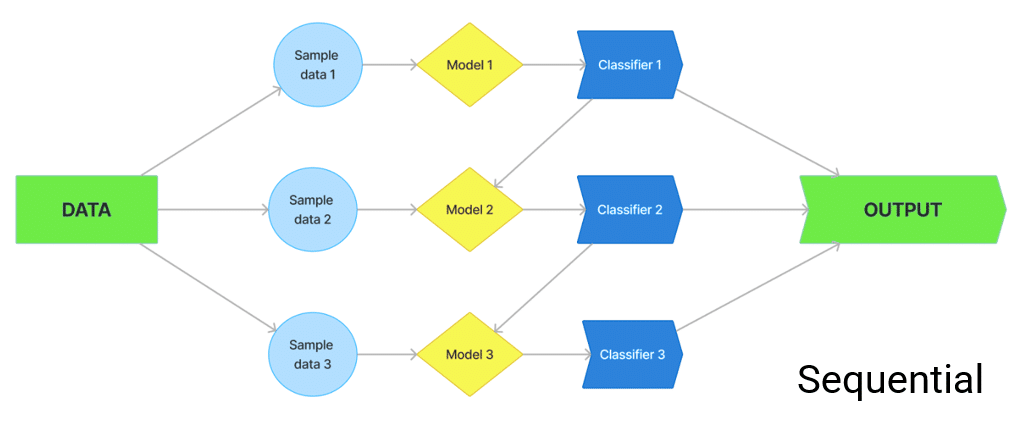
Different ensemble strategies have been developed over time, which results in a higher generalisability of learning models. Ensemble techniques work to improve prediction accuracy compared to a single classifier on the dataset. The two most popular ensemble techniques are Bagging and Boosting which are used to combine the results obtained by the machine learning methods.
Bagging algorithms
The bagging method is implemented to reduce the estimated variance of the classifier. The goal of the bagging ensemble method is to separate the dataset into several randomly selected subsets for training with substitution. These subsets of data are then trained using the same method used. The results obtained by each subset of data are then averaged, which provides better results compared to a single classifier.
Boosting algorithms
Boosting is an ensemble modelling method which tries to develop a robust classifier from the existing number of weak classifiers. To do this, a model is modelled using weak models in series. The development of this model is based on building each model by solving the errors of the previous model. This is done until either a proper prediction is established, or the maximum number of models is aggregated.
Though there is much more to the field of machine learning this was an approximation to the basics of it, as well as a quick look into some of its practical applications.